
-
TiBERT
To promote the development of Tibetan natural language processing tasks, we collects the large-scale training data from Tibetan websites and constructs a vocabulary that can cover 99.95% of the words in the corpus by using Sentencepiece. Then, we train the Tibetan monolingual pre-trained language model named TiBERT on the data and vocabulary. Finally, we apply TiBERT to the downstream tasks of text classification and question generation, and compare it with classic models and multilingual pre-trained models, the experimental results show that TiBERT can achieve the best performance.
Contributions
(1) To better express the semantic information of Tibetan and reduce the problem of OOV, We uses the unigram language model of Sentencepiece to segment Tibetan words and constructs a vocabulary that can cover 99.95% of the words in the corpus.
(2) To further promote the development of various downstream tasks of Tibetan natural language processing, We collected a large-scale Tibetan dataset and trained the monolingual Tibetan pre-trained language model named TiBERT.
(3) To evaluate the performance of TiBERT, We conducts comparative experiments on the two downstream tasks of text classification and question generation. The experimental results show that the TiBERT is effective.
-
Experimental Result:
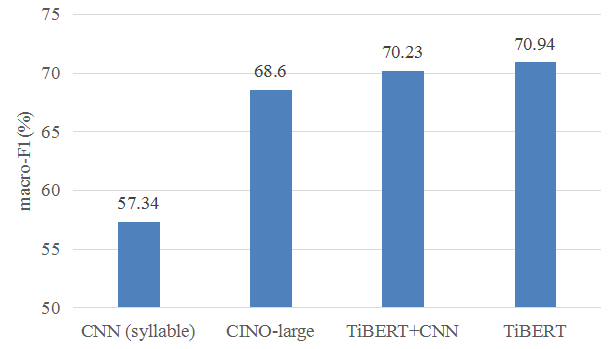
We conduct text classification experiments on the Tibetan News Classification Corpus (TCNN:https://github.com/FudanNLP/Tibetan-Classification) which released by the Natural Language Processing Laboratory of Fudan University for text classification.
Performances on title classification Performances on document classification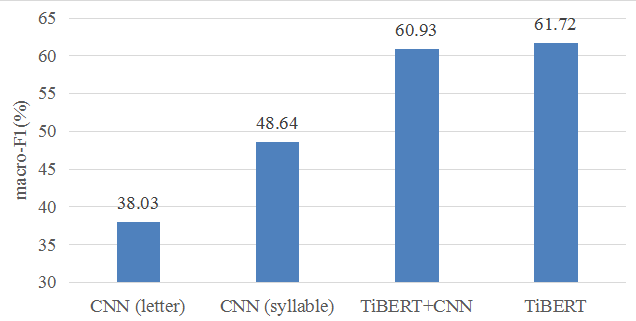
Download
Contact us
Email: TibetanQA_Office@163.comCite
S. Liu, J. Deng, Y. Sun and X. Zhao, "TiBERT: Tibetan Pre-trained Language Model*," 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2022, pp. 2956-2961, doi: 10.1109/SMC53654.2022.9945074.